Designing Video Surveillance Systems: Managing Owner’s Expectations

One of the most challenging aspects of designing modern video surveillance systems involves managing the Owner’s expectations. With the prevalence of large flat monitors and televisions in homes and the creative license of shows like CSI and NCIS, it is expected that security video cameras deployed on a site will provide crystal clear images where identification of a perpetrator will be possible regardless of the ambient light levels, weather conditions, or the perpetrator’s distance from the camera.
We have become use to the high definition screens: we see the news commentator on our home television with incredible detail, and football players performing on the field with close-up, slow motion and even stop action crystal clarity. Furthermore, we see the CSI lab scientist take a distorted reflection of an assailant off the chrome fender of a car and “enhance it” such that it becomes a courtroom worthy image of the perpetrator. So why shouldn’t security video cameras provide the same performance? While most realize that the sitcom and movie makers take some creative license and exaggerate the realities, daily exposure to this media creates unrealistic expectations.
Budget Battles
Construction is expensive, whether it’s the renovation of an existing building or complex, construction of new facilities, or an upgrade of a campus security system. With each of these cases, multiple disciplines are battling for available construction dollars. While security is seen as more critical than in past years, it is often thought of as the necessary evil, and most Owners do not want to spend any more money than necessary. However, when budget limitations are weighed against performance of the video surveillance system, too often the client’s specific expectations for each camera location are left undiscussed. This can result in a surprised and unhappy client when facial recognition is not achievable for the perpetrator of a crime in their parking lot. It may be a conscious decision not to have facial recognition for distant locations in the parking lot, once costs and other factors are discussed, but then the client won’t be surprised.
Performance in Low Ambient Light
One critical factor is the camera’s performance in various ambient light conditions. While low light performance capabilities have become quite good in some cameras, they are not so good in others. It’s a matter of physics. Specifically when larger pixel counts are spread over a single ⅓-inch sensor, each pixel receives less of the incoming light. When you divide a ⅓-inch sensor into 307,200 pixels (640 x 480), you have much larger pixels on the chips than when you divide that same size sensor into 5,038,848 pixels (2592 x 1944). The larger the pixel surface area, the more light it receives from the lens.
Better sensors have compensated for some of the inherent light degradation caused by larger pixel counts, but currently the better performance in low light situations seems to be limited to 1.3 megapixel cameras. Beyond this pixel count, the light availability has to be considerably greater to prevent excessive noise (image degradation) in the video image, and subsequent high bandwidth consumption.
In many cases, high quality video can be obtained by increasing ambient light levels and ensuring that the direction the light strikes potential intruders is commensurate with the direction of the video coverage. Where there is a concern for night time light levels, light pollution, or even energy use, supplemental light in the form of infrared lighting may be the solution. Still, care must be taken to insure the camera will go into night mode (producing a monochrome image) and remove the IR cut filter, for the infrared lighting to be of use. Thermal imaging cameras are another possible solution, but will be discussed in a later post.
Where existing ambient lighting conditions are questionable in terms of video camera choices available, a “live” onsite video image comparison of video from the various cameras may be warranted. Here various cameras from multiple manufacturers are set up side-by-side to observe the resulting images achieved under night-time conditions. The assistance of an integrator that installs multiple lines of cameras and has a stake in the outcome can be helpful. For example, on a recent campus upgrade project our firm had an integrator bring in multiple camera lines to test the quality of video achievable in low pressure sodium lighting. It was determined that infrared lighting would be needed. Infrared lighting units were brought in to test the theory. The results were not great, but were acceptable. All of this was done with Owner’s representatives onsite to view the results (from the facilities and the security departments). Again, the goal was to have no surprises.
The Reality of Image Detail
The reality of pulling image detail out of a live or recorded video image is limited by the fact that the detail must be in the image from the start. If we have a video image that contains 640 x 480 pixels (VGA), and take ¼ of the area (320 x 240 pixels) of the image and enlarge it (or blow it up) to be displayed on a 1920 x 1080 full-HD display, the video processor will produce many identical pixels for each single VGA pixel (effectively simply enlarging each pixel) creating a pixelated image.
A better way of defining image detail is by pixel density on a target (pixels per foot or pixels per meter). The 20 pixels/foot image in Figure 1 illustrates the kind of pixelization mentioned above. To obtain the level of image detail needed, we must select a camera and lens combination that will provide sufficient pixels per foot or pixels on target, whether that need be an identification, recognition, monitoring, or detection level of image detail.
If a camera’s purpose is simply to detect the presence of someone, 10 pixels per foot (33 pixels per meter) may be sufficient for an operator to detect a human presence. If the camera’s purpose is simply to monitor activity, 20 pixels per foot (66 pixels per meter) may allow the operator to discern some level of general activity. If face or license plate recognition is required, at least 45 pixels per foot (148 pixels per meter) should be obtained. Figure 1 illustrates the difference in image detail at various levels from 20 pixels per foot (66 pixels per meter) to 100 pixels per foot (328 pixels per meter). This image detail should be retrievable from either a live or archived image.

With the numerous possible camera and lens combinations, proper selection and application of the many possible camera types and formats can be a daunting task. This is made somewhat easier with a video surveillance design software that calculates the pixels per foot of the various views and illustrates the detail level with color coded field-of-view lines and crosshatching. These coded coverage patterns can be superimposed over drawings or Google Earth images if a scale is provided. Figure 2 illustrates this concept where the color codes indicate the following:
- Detecting: image detail of 10 pixels per foot (33 pixels per meter) required (color coded light blue).
- Monitoring: image detail of 20 pixels per foot (66 pixels per meter) required (color coded light green).
- Recognizing (a known person): image detail of 45 pixels per foot (148 pixels per meter) required (color coded light yellow).
- Identifying (an unknown person): image detail of 50 to 60 pixels per foot (165 to 197 pixels per meter) required (color coded light red).
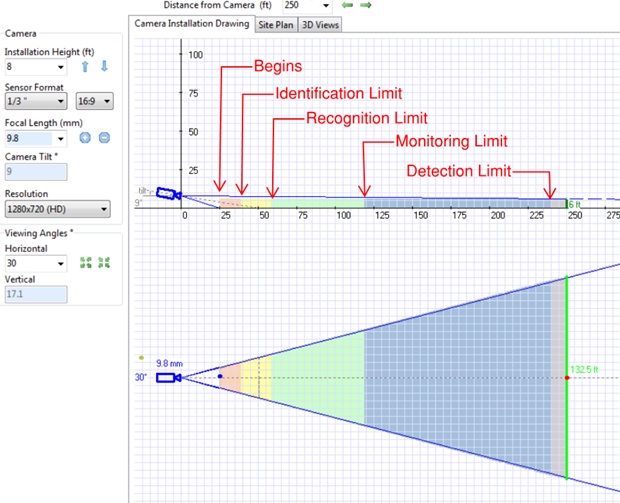
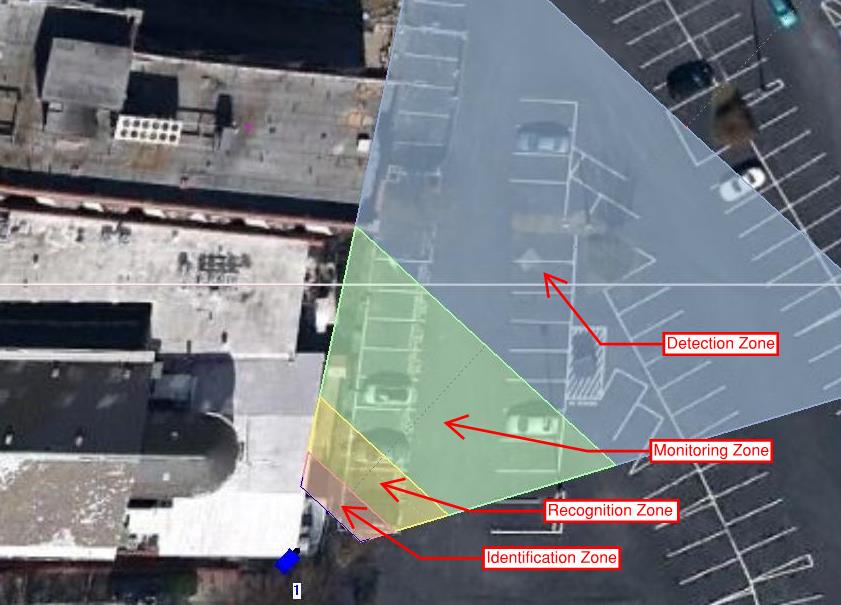
Figure 3 shows the various levels of image detail produced by a full HD (1920 x 1080 pixels) camera with a 4 mm focal length lens, and a ⅓-inch sensor when scaled and superimposed over a Google Earth image of a parking lot.
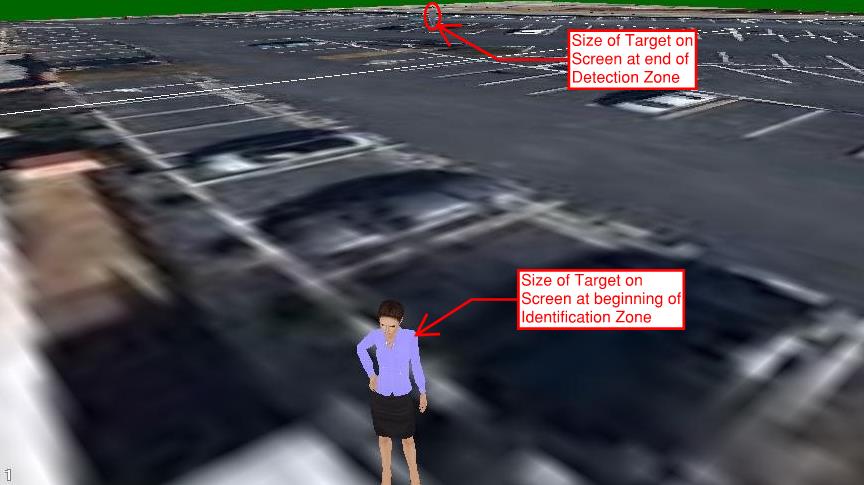
Figure 4 illustrates a simulated 3D screen display of human targets at the edges of these zones. As the figure indicates, the small human target at the edge of the detection zone is difficult to see. Most likely a human operator would not notice this person unless the clothing worn is highly contrasted with the background. Video analytics may detect the target, but that is another topic for another day.
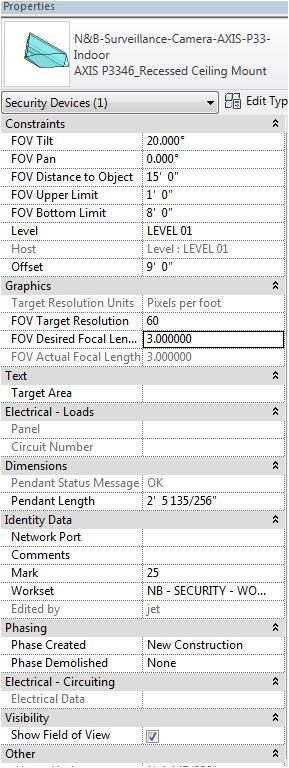
Some camera manufacturers have now created Revit families for their camera products that have parameters that allow the designer to model the camera view inside the Revit 3D Model.
Figure 5 shows an example screenshot of one of the family parameters chart. In this case Axis has provided a model of their Axis Model P3346 indoor recessed ceiling mount camera.
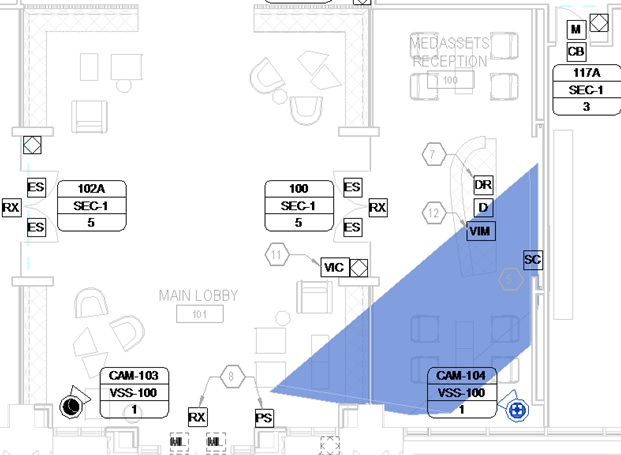
Figure 6 shows the camera’s angle of coverage in plan in plan view. Since the camera contains a varifocal lens the camera’s angle of coverage can be changed within the parameters of the camera.
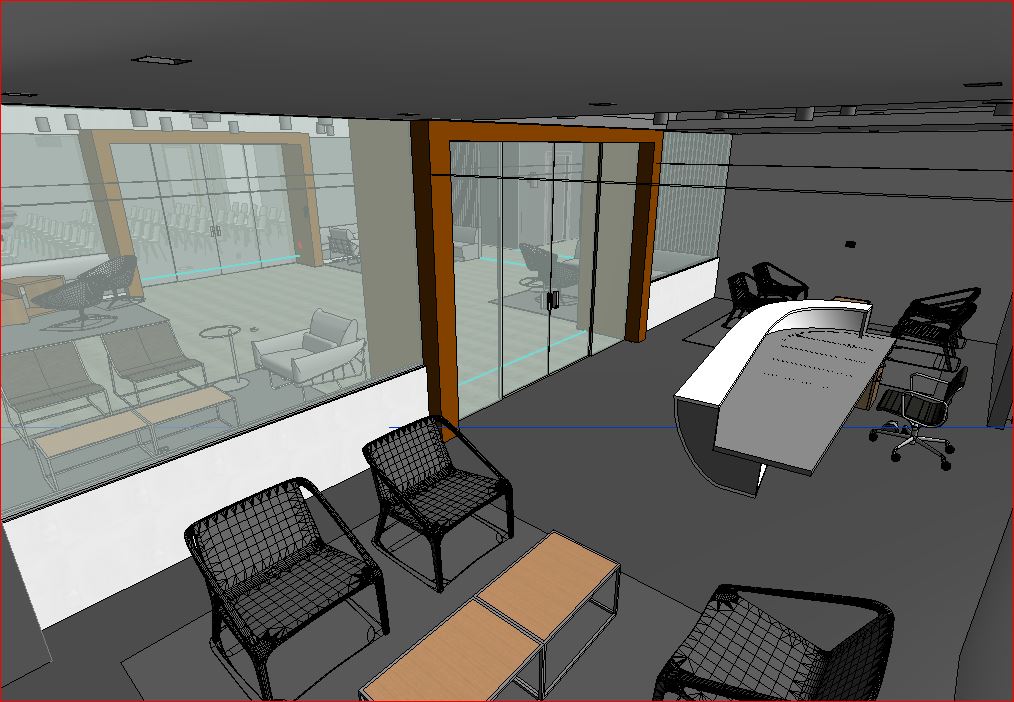
Figure 7 shows the 3D rendering of the cameras view based on the 3D model of the building’s interior also generated by the Revit Model. Images like these are invaluable in explaining what the owner might expect to see in terms of areas covered and size of objects on the display.
Conclusion
Daily exposure to high definition television media and police drama shows (like CSI and NCIS) may create unrealistic expectations as to what we will obtain when we implement a video surveillance system. The battle to get a budget that will provide the client with an acceptable image will generally involve a lot of discussions, illustrations of potential images based on camera types, camera and lens combinations, ambient light levels, and compromises. To prevent our clients from being disappointed when they view the implemented system, we must educate our clients in the reality of the situation. Specific discussions for each camera as to the desired results (identification, recognition, monitoring, or detection), the subsequent costs, and other variables that may affect the outcome will go a long way toward having a satisfied client.